Model Roundup: The Free Countdown, the $300 Amnesiac, and the Quiet Climber at #7
I check OpenRouter rankings every week to figure out which models to throw at my projects. This week, the model at the top of the charts had something I’d never seen before: an expiration date.
Right there on the Tencent Hy3 Preview page: “Going Away May 8.” Six days from now. And it’s currently generating 2.15 trillion tokens a week with a +1,356% spike. You know what that is? Not a sign of the best model on the market. It’s the AI equivalent of a store liquidation sale. Everyone’s grabbing tokens before they cost money.
That’s W18 in a nutshell. The #1 model is a countdown timer. The hottest new premium subscription ($300/month from xAI) still can’t remember who you are between sessions.
There’s good news buried in all this: Kimi K2.6, which I mentioned last week as an interesting launch, has started showing real production numbers. And there’s a model called Step 3.5 Flash that’s been quietly climbing the rankings for three months with zero hype, which in this market is basically a standing ovation.
Let me tell you what actually matters.
Table of Contents
- Table of Contents
- The #1 Model Is a Countdown Timer (Tencent Hy3 Preview)
- Kimi K2.6 Is Now a Real Recommendation
- The Sleeper: Step 3.5 Flash Has Been Climbing for Three Months
- Grok 4.3: Genuinely Impressive, Genuinely Annoying, $300/Month
- Your Smarter Model Might Be Breaking Your Agents
- What’s Actually Worth Using (and What’s Coming)
The #1 Model Is a Countdown Timer (Tencent Hy3 Preview)
Tencent launched Hy3 Preview on April 22 with a free access period that runs out May 8. That’s the entire explanation for the +1,356% weekly spike and the 2.15 trillion tokens burned. Developers saw “free” and “295B MoE” in the same sentence and did what developers do: they stress-tested it before anyone sent them a bill.
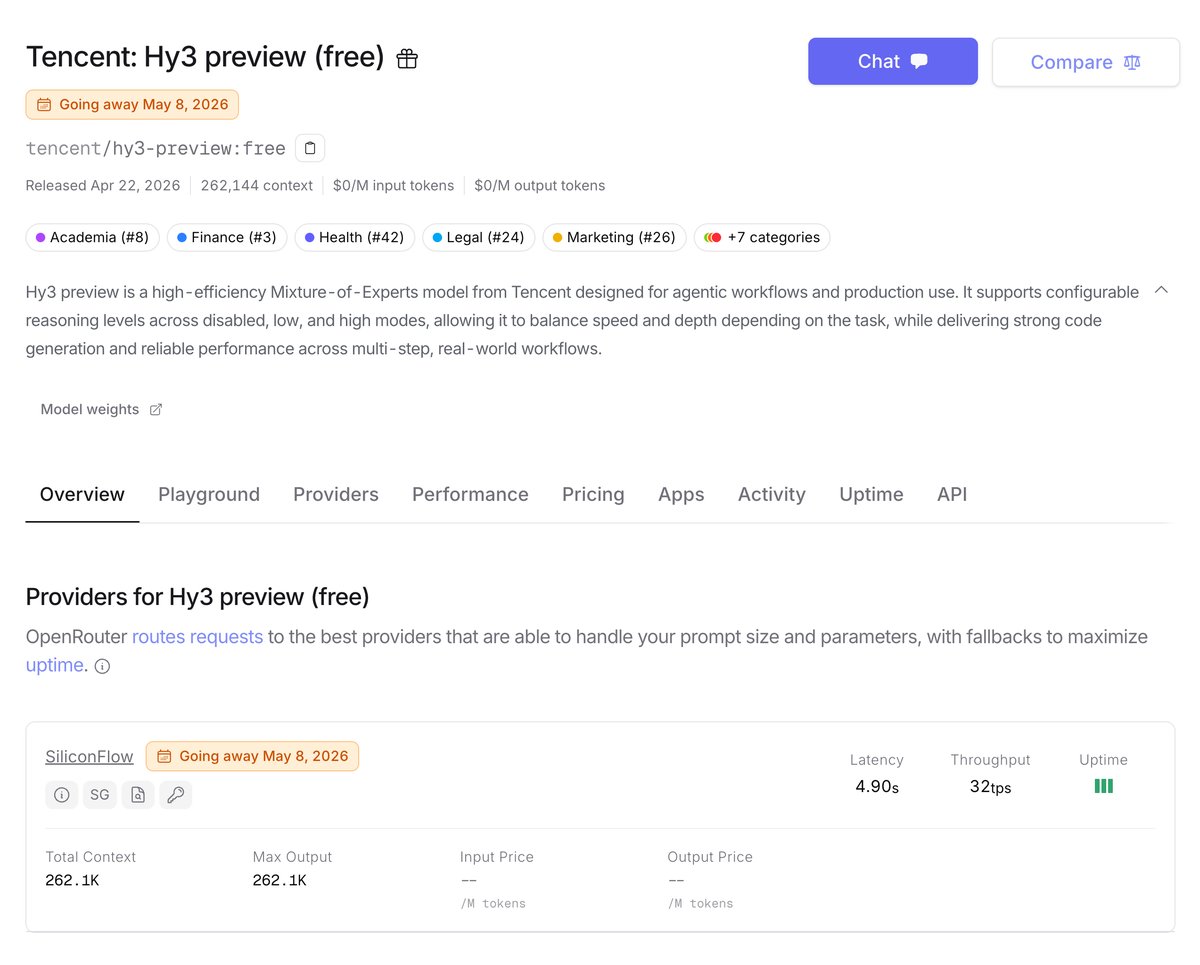
Here’s what Hy3 Preview actually is: 295 billion total parameters, 21 billion activated per token (mixture of experts, efficient by design), 262K context window, configurable reasoning you can dial from disabled to low to high. Designed for agentic coding workflows. On paper, solid.
In practice? No Arena votes because it’s too new to have accumulated any. No long-form reviews because nobody’s shipped anything with it yet. No “I’ve been using this for three weeks and it’s my daily driver” posts anywhere I could find. Just a lot of “grabbing free tokens before May 8” energy.
What happens after May 8 is the real question. Hy3 Preview becomes a paid model competing against DeepSeek V3.2 (which costs $0.14 input / $0.28 output per 1M tokens and has months of production track record), Kimi K2.6 ($0.74/$3.49 with confirmed adoption), and Step 3.5 Flash (which I’ll get to in a moment). Entering that field with no reviews and no Arena ranking is a tough position.
If you want to play with it before the deadline, go to openrouter.ai/tencent/hy3-preview:free and run some benchmarks. Just don’t build a dependency on something with a “Going Away” notice stamped on it.
Kimi K2.6 Is Now a Real Recommendation
Last week I called Kimi K2.6 an interesting launch. Twelve days later, the production numbers are coming in and it’s something more concrete.
Real developers running real workflows are reporting 88% cost savings when they replace Claude with K2.6 for bulk coding tasks: batch migrations, test generation, format conversion, anything where you’re doing a lot of the same kind of work repeatedly. The Kimi Code CLI, the companion tool for using K2.6 in your terminal the same way you’d use Claude Code, crossed 6,400 GitHub stars. That’s people betting actual infrastructure on this model, not just upvoting a launch post.
The pattern hardening into consensus across forums: use K2.6 for bulk, use Claude for the high-stakes core. At $0.74 input / $3.49 output per 1M tokens, K2.6 is roughly 4x cheaper than Claude Sonnet 4.6. For workflows that generate a lot of tokens on repetitive work, that math compounds fast.
Where K2.6 Falls Short
This is the part I actually care about more than the hype. K2.6 trails GPT-5.4 on GPQA-Diamond (90.5% vs 92.8%) and AIME 2026 (96.4% vs 99.2%). These are hard reasoning benchmarks. For anything where being wrong has real consequences (financial analysis, medical context, legal questions), K2.6 is not the answer. The cost savings don’t matter if the output costs you more to fix.
Use it for code. Trust it with the boring high-volume stuff. Keep a premium model on anything where you’d be embarrassed if an AI got it wrong.
K2.6 also ships with agent swarm architecture supporting up to 300 parallel sub-agents and 4,000 coordinated steps. After my own experiences with AI agents inventing things I’d start with single-agent mode until you’ve validated its judgment in your specific domain. 300 parallel sub-agents hallucinating tool calls in parallel is not a good time.
The Sleeper: Step 3.5 Flash Has Been Climbing for Three Months
Most models follow the same OpenRouter arc: spike at launch, plateau after a few weeks, slowly fade as the next shiny thing arrives. Step 3.5 Flash doesn’t fit this pattern.
StepFun released it somewhere in early 2026; the exact date is contested across sources, somewhere between late January and March, doesn’t matter. As of this week it’s at #7 on OpenRouter with +28% week-over-week. For a model that’s been around three months, that’s not a hype spike. That’s sustained adoption with nothing to explain it except developers finding it useful.
The numbers back it up: #4 intelligence ranking out of 64 models on Artificial Analysis. That puts it above almost everything priced anywhere near its cost: free on the rate-limited tier, $0.10 input / $0.30 output per 1M tokens on paid. For comparison, DeepSeek V3.2 costs $0.14/$0.28 and ranks lower on the same index. Step 3.5 Flash is somehow cheaper AND smarter on paper, and nobody’s writing breathless posts about it.
Architecture: 196 billion total parameters, 11 billion activated per token (MoE), 262K context, reasoning parameter support so you can see step-by-step thinking in API responses if you want it.
The One Real Catch
Step 3.5 Flash is extremely verbose. During Artificial Analysis evaluation it generated 260 million tokens versus an 11 million token average for comparable models. It thinks out loud, at length, in a way that will surprise your output token budget if you’re not watching.
Set max_tokens limits. If you’re using it for any high-volume generation, put a ceiling on it. Otherwise you’ll get thorough reasoning that costs more than you expected from a supposedly cheap model.
Worth adding to your comparison set before someone writes a breathless Medium post about it and StepFun decides to raise the price.
Grok 4.3: Genuinely Impressive, Genuinely Annoying, $300/Month
Let’s do the good news first, because there’s real good news here.
Grok 4.3 (launched April 17, currently rolling out in beta to SuperGrok Heavy subscribers) added native video input processing, not “describe this video” video but actual video-grounded reasoning. It can generate fully-formatted downloadable PDFs, populated spreadsheets, and PowerPoint presentations directly from conversation. Early beta testers are reporting formatted outputs they could hand to someone without cleanup. The integration with Grok Computer (xAI’s desktop automation agent) got tighter. If you’re doing autonomous desktop workflows, Grok 4.3 has a real story.
Now the bad news.
Grok 4.3 costs $300/month. That’s $100 more than ChatGPT Pro and $100 more than Claude Max. Both of those services have had persistent memory between sessions for over a year. Grok 4.3 does not. Every time you close your tab, the model forgets you. You start over. Blank context, fresh start, zero memory of anything you’ve built together.
Persistent memory is not on xAI’s published roadmap.
Multiple reviewers landed on the same observation this week. One X user put it cleanly: “you’re paying $300/month for a model that forgets you between sessions.” That’s not exaggeration. That’s the product.
At $200/month, this would be annoying. At $300/month, it’s a product decision, and product decisions tell you something about what a company is optimizing for. xAI built the video capabilities and the document generation first. Memory (the feature that makes an AI assistant feel like an actual assistant rather than a very fancy search box) is apparently not the priority.
Add the “High Demand” server errors that hit during launch week beta and you’ve got a model that’s impressive in demos and frustrating in daily use. The full API rollout is coming mid-to-late May. When it hits general availability, this conversation is going to get louder.
Your Smarter Model Might Be Breaking Your Agents
This one’s structural rather than model-specific, and it’s relevant for anyone running agentic pipelines.
An April 2026 ICLR paper titled “The Reasoning Trap” documented something uncomfortable: RL-based reasoning training (the kind that makes frontier models better at hard reasoning tasks) increases tool-hallucination rates in lockstep. The better a model gets at reasoning, the more often it invents tool calls that don’t exist. Function names, API endpoints, methods that aren’t in your schema. The model reasons its way to a call it can’t actually make.
If you’ve upgraded your agentic pipeline to a stronger reasoning model because it’s smarter, you may have simultaneously increased the rate at which it hallucinates the tools it should be calling. The capability and the failure mode scale together.
I’ve written about running into this firsthand with OpenClaw. The model-specific details differ but the pattern is the same. Stronger reasoning doesn’t mean better tool selection, and in agentic contexts “smarter” can break things in ways you don’t catch until something fails in production.
Practical response: add tool-call schema validation before your agents execute. Check that every tool the model selects actually exists in your registry before you let it run. This applies to every frontier RL-trained model right now. It’s not a specific model bug, it’s how these systems are being trained.
What’s Actually Worth Using (and What’s Coming)
Quick reference:
| Tier | Model | Input $/1M | Output $/1M | Best For |
|---|---|---|---|---|
| Free (grab it now) | Hy3 Preview | $0 | $0 | Experiments before May 8 only |
| Free (stable) | Step 3.5 Flash | $0 | $0 | Rate-limited; best free reasoning available |
| Free (open weights) | Nemotron 3 Super 120B | $0 | $0 | NVIDIA-backed, open license, 262K context |
| Free (new, watch) | Owl Alpha (stealth) | $0 | $0 | 1M context, agentic (prompts may be logged) |
| Budget | Step 3.5 Flash (paid) | $0.10 | $0.30 | Climbing for 3 months, verbose but smart |
| Budget | DeepSeek V3.2 | $0.14 | $0.28 | Proven track record, still the value baseline |
| Mid | Kimi K2.6 | $0.74 | $3.49 | Bulk coding workflows, 88% cheaper than Claude |
| Mid | Gemini 3.1 Pro | $2.00 | $12.00 | Arena #4 overall, 1M context |
| Premium | Claude Sonnet 4.6 | ~$3.00 | ~$15.00 | #2 Arena coding, proven daily driver |
| Premium | Claude Opus 4.7 | $5.00 | $25.00 | #1 Arena overall (thinking mode), high stakes |
Mark your calendar for May 19. Google I/O is 17 days away. Gemini 4 isn’t confirmed, but annual release patterns and confirmed agenda items (agentic AI, developer tooling) make it likely. That’s the next likely shakeup in this table.
Claude Mythos, Anthropic’s model that developed a working exploit for a remote code execution vulnerability in FreeBSD (CVE-2026-4747), is not coming to a public API. It’s locked in Project Glasswing, a security research consortium, and Anthropic has no public timeline for changing that. Mention it at parties.
GPT-6 is still vaporware. Polymarket has it at 84% by December 31, 2026. That’s not a date, it’s a guess with confidence bounds.
The model worth your attention this week isn’t at #1. It’s at #7, three months old, climbing steadily, no hype cycle to explain it. Step 3.5 Flash just keeps showing up in the data.
Related Posts

April 2026 Model Roundup: Opus 4.7 Official, DeepSeek V4 Open-Sources 1M Context, and GPT-5.5 Upstaged the GPT-6 Hype
Claude Opus 4.7 officially landed and is already number 1 on Arena. Kimi K2.6 open-sourced a trillion-parameter coding model. GPT-5.5 shipped yesterday inste...