
April 2026 Model Roundup: Opus 4.7 Official, DeepSeek V4 Open-Sources 1M Context, and GPT-5.5 Upstaged the GPT-6 Hype
Two weeks ago this month, developers discovered their Gemini API bills had exploded. Google’s billing system was charging for approximately 114 internal search queries per API call with grounding enabled. That was the story I started writing. By the time April 24 arrived, three new models had officially launched, the “Still Waiting for GPT-6” watch ended not with GPT-6 but with GPT-5.5, and DeepSeek V4 dropped today with a 1M context window under Apache 2.0, on the same day GPT-5.5 went live, apparently just to split the news cycle.
This roundup covers April 2026 so far.
Table of Contents
- When Google Billed 114x
- What Actually Moved This Week
- Claude Opus 4.7 Is Official — and the Cost Story Is Better Than Expected
- Hype Check: Mimo V2 Pro, One Month In
- Kimi K2.6: The Open-Source Agentic Coding Model Nobody Covered
- Meta Broke Open Source Hearts
- The Models That Cost Almost Nothing (No, Really)
- GPT-5.5 Shipped Yesterday, Not GPT-6, and DeepSeek V4 Dropped Today
- The Actual Takeaways
- Read for Yourself
When Google Billed 114x
Gemini 3 Flash Preview is Google’s high-volume, reasonably priced model: $0.50/M input, $3/M output, 1M context window. It’s been running at #4 on OpenRouter by weekly token volume. A lot of people have pipelines running on it. The “search grounding” feature, which lets the model query Google Search to ground its responses in real-time information, sounds great on paper.
Turns out the billing for that feature had a misconfiguration. For every API call, users were being billed for roughly 114 separate search queries rather than the actual number of queries they used. The “Generate content search query Gemini 3” SKU in users’ dashboards was showing 10-15x the expected line items. Actual grounding call frequency had decreased, but bills exploded anyway.
The scale of damage before Google caught it:
- Multiple developers reporting 4x–10x cost increases on flat or declining usage
- €1,000+ additional daily costs for at least one European developer
- ₩340,000 in two days for a Korean developer
- Google identified the root cause on April 14, committed to fixing the misconfiguration and correcting previous bills
Update as of April 24: Google engineer Ali Cevik confirmed on the developer forum that the billing misconfiguration is fixed going forward. Refunds are being processed, but Google has provided no specific timeline. Forum responses from their team said “by the end of the month” without committing to anything more specific. Affected users are reporting that support is framing corrections as “one-time exceptions” rather than acknowledging the systemic bug. Re-enabling grounding is probably safe now for new calls, but check your billing dashboard before turning it back on, and watch the first few days’ charges carefully.
The thread on the Google AI Developers Forum is worth reading if you’re running anything on Gemini 3 Flash with grounding enabled. The concrete lesson here: search grounding is billed separately from token usage, and before you enable any “enhanced” feature on a high-volume model, understand exactly what gets metered and how. Don’t assume the main pricing page tells the whole story.
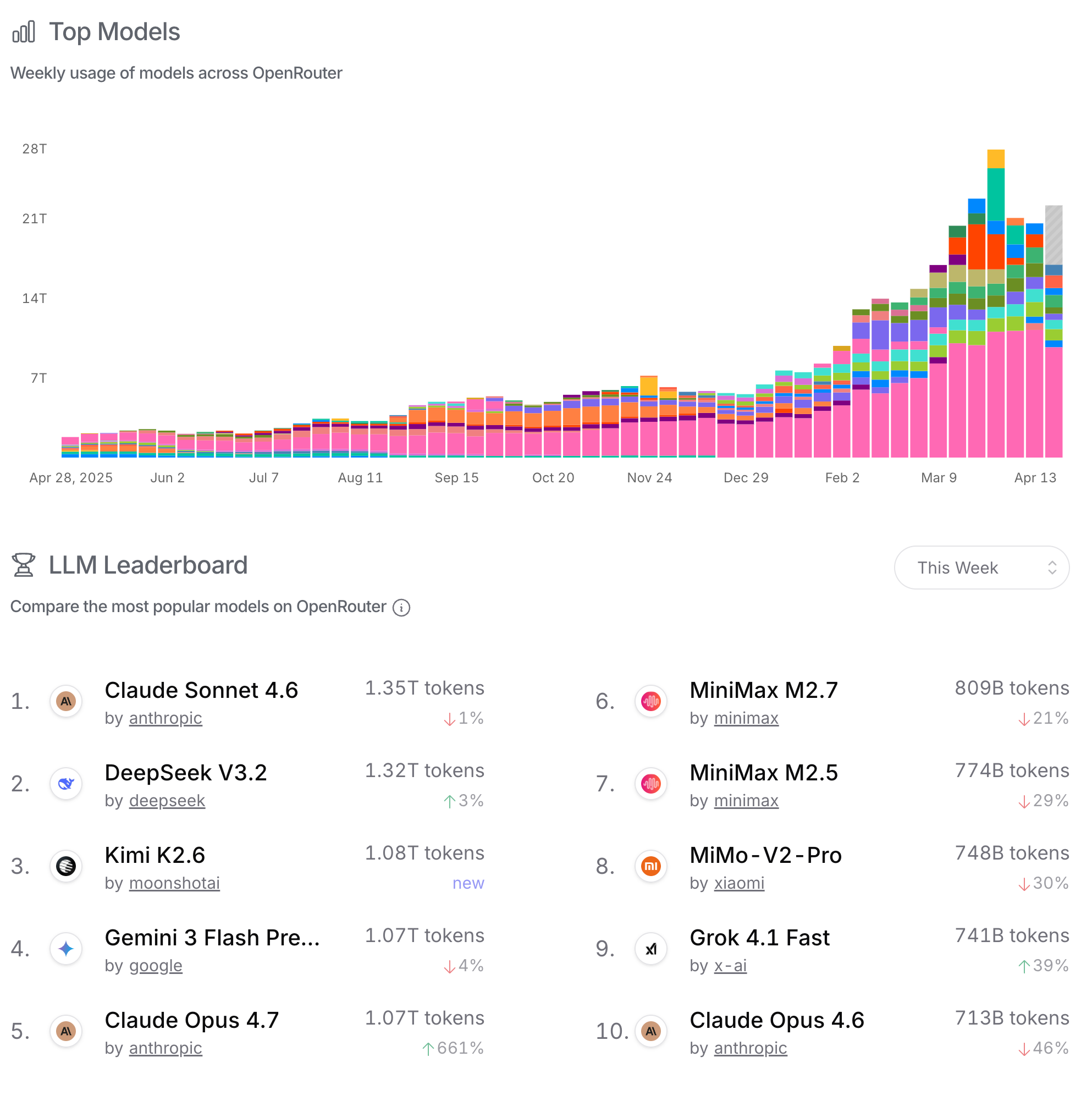
What Actually Moved This Week
Here’s the OpenRouter picture as of the week ending April 24:
| Rank | Model | Provider | Weekly Tokens | WoW Change | Arena Overall |
|---|---|---|---|---|---|
| 1 | Claude Sonnet 4.6 | Anthropic | 1.38T | +3% | #3 (1496) |
| 2 | DeepSeek V3.2 | DeepSeek | 1.32T | +3% | — |
| 3 | Gemini 3 Flash Preview | 1.11T | stable | — | |
| 4 | Claude Opus 4.7 | Anthropic | 951B | +4,221% | #1 (1503, thinking) |
| 5 | Mimo V2 Pro | Xiaomi | 902B | +9% | not yet |
| 6 | MiniMax M2.5 | Minimax | 856B | +22% | — |
| 7 | MiniMax M2.7 | Minimax | 813B | +24% | — |
| 8 | Kimi K2.6 | Moonshot AI | 792B | New | not yet |
| 9 | Claude Opus 4.6 | Anthropic | 756B | +46% | #2 (1503, thinking) |
| 10 | Grok 4.1 Fast | X.AI | 700B | +33% | — |
Three new entries this week: Claude Opus 4.7 at #4 with a 4,221% spike, Kimi K2.6 debuting at #8 on its first week, and Grok 4.1 Fast at #10. Claude Opus 4.6, which was briefly the second-most-used model, dropped to #9 as people migrated to 4.7.
The stable story continues in the background: Claude Sonnet 4.6 and DeepSeek V3.2 are running neck and neck at the top, both at a slow +3% WoW. That’s real production traffic, not evaluation runs.
Claude Opus 4.7 Is Official — and the Cost Story Is Better Than Expected
Anthropic launched Claude Opus 4.7 on April 16. It’s been sitting in Arena’s blind comparison system for a few weeks, and it’s now publicly available on the API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry.
Pricing: $5/M input, $25/M output — unchanged from Opus 4.6. That’s the headline.
The real story is what the model does to your costs in practice. Artificial Analysis ran Opus 4.7 through their GDPVal-AA benchmark suite (44 occupations, 9 industries) and found it uses roughly 35% fewer output tokens than Opus 4.6 to complete the same tasks. The practical effect: real-world costs on Opus 4.7 run approximately 11% lower than Opus 4.6 at the same stated price per token.
There’s a caveat on the input side. The 4.7 tokenizer is less efficient, generating up to 35% more tokens from the same input text depending on content type. For workloads with heavy, repeated system prompts or long document context, this can offset some of the output savings. Prompt caching (available at roughly 10% of the input rate) largely neutralizes this.
Performance numbers that matter:
- Artificial Analysis Intelligence Index: 57 (up 4 points from Opus 4.6, tied with GPT-5.4 and Gemini 3.1 Pro)
- GDPVal-AA: 1,753 Elo — 79 points ahead of the next model on real-world knowledge work
- Hallucination rate: 36% (down from 61% on Opus 4.6, achieved through more frequent abstention)
- Arena: #1 tied at 1503 Elo (with thinking mode), #4 at 1494 without thinking
The 4,221% WoW spike on OpenRouter is a curiosity spike plus a migration wave from people moving from 4.6. By next week you’ll see whether it settles into stable sustained usage or was just upgrade traffic.
New cybersecurity guardrails: Anthropic added automatic detection and blocking for prohibited cybersecurity uses. Security professionals doing legitimate work (pen testing, vuln research, red-teaming) need to join their new Cyber Verification Program to preserve access to those capabilities on 4.7.
Hype Check: Mimo V2 Pro, One Month In
Mimo V2 Pro shot up 140% WoW in the April 14 data. Now, with another week of data, it’s at +9%. The spike is over and it’s settling into a real usage tier.
Xiaomi’s flagship foundation model: over 1 trillion total parameters, 42 billion active (MoE architecture), $1/M input, $3/M output, 1 million token context window. Benchmarks put it at 49 on the Artificial Analysis Intelligence Index.
The +140% spike was the evaluation-and-curiosity phase. The +9% continuing growth suggests people who ran it liked it enough to keep using it. Still no Arena votes worth analyzing. At ~5 weeks old, the model hasn’t been around long enough for production validation at scale.
Check back in 2–3 more weeks. If it accumulates Arena votes and holds a respectable position there, the benchmarks were real. Stable OpenRouter usage without Arena presence is ambiguous: it could mean quality users who prefer specific capabilities, or it could mean low-friction API access driving test traffic.
Kimi K2.6: The Open-Source Agentic Coding Model Nobody Covered
Moonshot AI released Kimi K2.6 on April 20 and it debuted at #8 on OpenRouter in its first week. You probably missed it because the same week had Claude Opus 4.7’s official launch, Grok 4.3 Beta, and the GPT-5.5 pre-announcement noise.
What it is: a 1-trillion-parameter MoE model with 32B active parameters, 262,144-token context window, vision, and agentic capabilities. Weights published on Hugging Face under a Modified MIT License: full open weights, commercially usable.
What it’s built for: long-horizon coding agents, front-end generation from natural language, and massively parallel agent swarms. Moonshot’s documentation specifically highlights scaling to 300 sub-agents and 4,000 coordinated steps in a single session. If you’re building orchestration-heavy multi-agent systems, this is the open-weight model that was designed from the ground up for that use case.
Benchmark comparisons are mixed but solid. On SWE-Bench Pro it outperforms DeepSeek V4-Pro (58.6 vs 55.4). On LiveCodeBench it trails V4-Pro (89.6 vs 93.5). On competitive coding (Codeforces), both trail GPT-5.5.
No pricing table yet because it’s primarily a self-hosted model. Kimi API pricing for hosted inference isn’t broadly published yet. For the open-weights version: the cost is your inference infrastructure. A 32B-active MoE runs reasonably on mid-tier GPU setups.
DeepSeek V4 (more on that below) is the stronger model by most closed benchmarks. But Kimi K2.6 has the context window advantage (262K vs 1M for V4-Pro — actually V4-Pro wins there), and the MIT-derived license is cleaner than Apache 2.0 for certain commercial use cases.
Meta Broke Open Source Hearts
Llama made Meta relevant in the AI developer world. Open weights, commercial use, the whole deal. Llama 4 dropped in 2025 with a 10 million token context window and impressive parameter counts. The developer community built on it. People ran it locally, fine-tuned it, deployed it. Meta was the company that understood that open source was ecosystem building.
Then on April 8, Muse Spark dropped from Meta’s new “Superintelligence Labs.” Proprietary model. Not open weights. API in private preview. To try it on the web, you need a Facebook or Instagram login.
Meta went from an Artificial Analysis Index score of 18 with Llama 4 Maverick to 52 with Muse Spark. That’s not a modest improvement. And in Arena’s head-to-head voting, Muse Spark is sitting at #6 overall with an Elo of 1492, beating GPT-5.4-high in actual user preference votes.
So the model is legitimately good. As of April 24, the API remains private preview only: no public access, no announced pricing, no timeline for broader availability. Priority access is going to healthcare, education, and enterprise research partners. If you’re building something that needs Muse Spark today, you’re waiting.
“Meta learned from OpenAI: make the good stuff closed, give the community the crumbs.” I’ve been seeing that take everywhere this month, and I don’t think it’s entirely wrong.
The broader question this raises: if every lab eventually closes off its best models, what’s the long-term roadmap for building on open weights? DeepSeek and Moonshot are still playing the open-source game. Kimi K2.6 is MIT-licensed. And DeepSeek V4 dropped today with Apache 2.0 weights on Hugging Face. The pattern is becoming hard to ignore, but there are still holdouts.
The Models That Cost Almost Nothing (No, Really)
I need to talk about MiniMax M2.5 because I’ve been mentioning it in passing and it deserves its own paragraph.
$0.118 per million input tokens.
That’s twelve cents per million tokens. For a model that’s sitting at #6 on OpenRouter by weekly volume and growing at 22% WoW. For a model that scores 80.2% on SWE-Bench Verified: which is roughly what Claude’s flagship hits. With a 196,608 token context window. And it’s good enough at agentic tasks that it’s been called out repeatedly in the Latent.Space local model community as the go-to for tool-heavy applications.
The pricing table this week:
| Model | Input $/1M | Output $/1M | Context | Notes |
|---|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 | 1M | Arena #1 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M | #1 volume on OR |
| GPT-5.5 | $5.00 | $30.00 | 2M | Tops AA Index at 60 |
| GPT-5.5 Pro | $30.00 | $180.00 | 2M | Research tier |
| DeepSeek V4-Pro | $1.74 | $3.48 | 1M | Apache 2.0, released today |
| DeepSeek V4-Flash | $0.14 | $0.28 | 1M | Apache 2.0, released today |
| DeepSeek V3.2 | $0.259 | $0.42 | 163K | 3-mo validated, #2 on OR |
| MiniMax M2.5 | $0.118 | $0.99 | 196K | 80.2% SWE-Bench |
| MiniMax M2.7 | $0.30 | $1.20 | 196K | Upgraded M2.5 |
| Mimo V2 Pro | $1.00 | $3.00 | 1M | Settling into usage |
| Gemini 3 Flash | $0.50 | $3.00 | 1M | Grounding: proceed cautiously |
When MiniMax M2.5 matches or beats Sonnet on SWE-Bench at roughly 1/25th the per-token cost, we’re in strange territory. Either the benchmark is missing something important about real-world usability, or there’s value being left on the table by anyone running default Claude endpoints on agentic coding tasks without at least testing alternatives.
My actual picks this week, by use case:
- Budget, coding/agentic: DeepSeek V4-Flash at $0.14/M: just dropped today, open source. Test it immediately. MiniMax M2.5 at $0.118/M is still the safety pick if you want community-validated quality.
- Budget, general: DeepSeek V3.2. $0.42/M output, three months of community validation, strong on math and code. Nothing changed here.
- Balanced: DeepSeek V4-Pro at $1.74/M input, $3.48/M output with 1M context. Undercuts everything at this quality tier by a factor of 5-8x.
- Premium, coding: Claude Sonnet 4.6 or Claude Opus 4.7 depending on your task complexity and whether the token economics work out (see the next section).
- If you have to have the absolute best: Claude Opus 4.7 with thinking (Arena #1, 1503 Elo) or GPT-5.5 (AA Index #1 at 60). Accept the pricing gap vs open-source alternatives.
The Hidden Tax: How Sonnet 4.6 Can Still Cost More Than Opus
Claude Sonnet 4.6 is marketed as the economical alternative to Opus. It’s $3/M input versus Opus 4.7’s $5/M: a modest 1.67x difference on input. But that’s not where your money goes on agentic workloads.
On the Artificial Analysis GDPVal-AA benchmark, Sonnet 4.6 generates 4.5x more output tokens than Opus 4.6 to complete the same tasks. The model isn’t worse. It’s producing more intermediate reasoning, more scaffolding, more steps. But output tokens are what you pay for.
The math with correct current pricing: Sonnet 4.6 at 4.5x tokens × $15/M output = $67.50/M effective output cost versus Opus 4.7 at $25/M output. Sonnet costs 2.7x more per equivalent task in heavy agentic use.
The practical takeaway: if you’re running document summarization, one-shot Q&A, light code generation, Sonnet 4.6 is cheaper and you should use it. If you’re running agentic pipelines, autonomous coding agents, extended tool-use workflows: benchmark on your actual workload before you assume Sonnet saves money. The pricing page isn’t lying; the intuitive comparison probably is.
And now there’s a third option in the mix: Opus 4.7, which uses ~35% fewer output tokens than Opus 4.6 at the same $25/M rate. For heavy agentic use, Opus 4.7 may be the cheapest of the three Anthropic options. Run your own numbers.
GPT-5.5 Shipped Yesterday, Not GPT-6, and DeepSeek V4 Dropped Today
OpenAI finished pre-training the model codenamed “Spud” on March 24. An April 14 release date came and went with nothing. Then on April 23, OpenAI shipped GPT-5.5 — their most capable model to date and, per their description, the first fully retrained base since GPT-4.5.
It’s not GPT-6. But it’s real.
GPT-5.5 numbers:
- Artificial Analysis Intelligence Index: 60 — three points ahead of Claude Opus 4.7 and Gemini 3.1 Pro Preview, both at 57
- Terminal-Bench 2.0: 82.7% (vs 75.1% for GPT-5.4)
- Expert-SWE: 73.1% (vs 68.5% for GPT-5.4)
- Pricing: $5/M input, $30/M output — double the cost of GPT-5.4 on output
- GPT-5.5 Pro tier: $30/M input, $180/M output (research/enterprise)
- Context window: 2M tokens (1M longer than most competitors)
The 40% reduction in output token usage that OpenAI claims keeps the effective cost increase to roughly 20% despite the doubled price per token. That math depends entirely on your workload matching the benchmark profile.
Now the same-day plot twist: On April 24 — today — DeepSeek V4 dropped with open weights under Apache 2.0.
DeepSeek V4-Pro: 1.6T total parameters, 49B active (MoE), 1M context window, $1.74/M input, $3.48/M output. V4-Pro output is 8.6x cheaper than GPT-5.5 and 21x cheaper than Claude Opus 4.7 at stated per-token rates.
DeepSeek V4-Flash: 284B total parameters, 13B active, 1M context, $0.14/M input, $0.28/M output.
Both variants under Apache 2.0, weights on Hugging Face and ModelScope today.
Performance on competitive coding (Codeforces): V4-Pro scores 3,206 vs GPT-5.5’s 3,168 — V4-Pro wins. On SWE-Bench Pro, Kimi K2.6 beats V4-Pro (58.6 vs 55.4). On long-context retrieval (MRCR 1M), Claude Opus 4.6 beats V4-Pro (92.9 vs 83.5). So V4-Pro isn’t universally better — but at $3.48/M output vs $25-30/M for closed alternatives, it doesn’t need to be universally better to be the right answer for most workloads.
GPT-6 “Spud”: still hasn’t arrived. Polymarket has it at 72% by April 30 and 95%+ by June 30. At this point I’ll believe it when I see it.
Other things still in the pipeline:
- Claude Mythos Preview: still available only to approximately 50 partner organizations since April 7. Cybersecurity focus. $25/M input, $125/M output. Nothing changed here.
- Grok 4.3 Beta: dropped April 17 with native video understanding, PDF/PowerPoint generation, and enhanced long-context processing. Not yet on OpenRouter broadly. Still in xAI testing phase.
The Actual Takeaways
April 2026 shipped more major model releases than any previous month in AI history, and then DeepSeek V4 and GPT-5.5 both dropped on the same day at the end of it. The landscape looks different today than it did two weeks ago.
What actually matters as of April 24:
Gemini 3 Flash grounding billing is fixed going forward but check your billing dashboard before re-enabling, and watch the first few days’ charges carefully. Refunds are in process; don’t expect speed on that.
DeepSeek V4 just dropped open-source with 1M context and Apache 2.0. V4-Flash at $0.14/$0.28 and V4-Pro at $1.74/$3.48. Test it today. It’s too new for community validation but the pedigree is real and the pricing is absurd for the quality tier.
MiniMax M2.5 at $0.118/M and 80.2% SWE-bench is still the community-validated budget pick for agentic coding. Three weeks of steady usage volume with no hype cycle. DeepSeek V4-Flash is the new challenger — if validation holds over the next few weeks, it may displace M2.5.
Claude Opus 4.7 is the easiest top-tier upgrade you’ll make this month. Same price as 4.6, 35% fewer output tokens, Arena #1. If you’re running Opus 4.6 today, just switch.
Benchmark Sonnet 4.6 vs Opus 4.7 on your actual agentic workloads. Opus 4.7’s improved token efficiency means the economics may favor it over Sonnet for complex agent tasks. Run the math on your usage before assuming Sonnet is cheaper.
Mimo V2 Pro and Kimi K2.6 need another 2-3 weeks. Both show real usage momentum. Neither has Arena data yet. Hold the investment thesis pending community validation.
GPT-5.5 topped the Artificial Analysis Intelligence Index at 60. That matters, but at $30/M output you’re paying a substantial premium over DeepSeek V4-Pro ($3.48/M) for about 3 points on a benchmark. Evaluate whether that delta maps to your actual workload before committing.
The model evaluation cycle for “is this the right choice?” is now measured in weeks, not quarters
Read for Yourself
- Gemini 3 Flash billing bug thread — r/[Google AI Dev Forum] — Developer discussion of the billing disaster, with cost breakdowns and screenshots
- Meta introduces Muse Spark — TechCrunch — The story of Meta’s open-source pivot; comment threads are heated
- Top Local Models List April 2026 — Latent.Space — Community-validated rankings for open-weight models
- Mimo V2 Pro: mistaken for DeepSeek V4 — Decrypt — The review that captures the week’s Xiaomi surprise
- Claude Sonnet 4.6: the workhorse that ate the flagship — AwesomeAgents — Honest multi-week review with the token cost caveat
Related Posts
Model Roundup: The Free Countdown, the $300 Amnesiac, and the Quiet Climber at #7
Tencent's Hy3 Preview is #1 on OpenRouter this week because it's free until May 8. Here's what's actually worth building on.