
Claude + MCP - 'Vibe Coding' Without Specialized IDEs Part 1
First, I have to say I hate the term “vibe coding”. But I was curious after seeing some of the apps that were built this way. It took a while, because I have had a CoPilot subscription for over a year and while it helps with things, it also is very stupid. My biggest pet peeve is this common cycle (paraphrased):
- Me: I get this error on this line
- CoPilot: Try this code
- Me: Is your code any different than mine?
- CoPilot: Yes, I blah, blah, blah…
- Me: I did a diff and your code is no different
- CoPilot: Try this code
- Me: That looks the same also. Can you see the file I added? Do a manual comparison, line by line.
- CoPilot: You are right, my code is the same as yours.
- Me: So how does your code fix the error if it is no different?
- (Cycle starts over again from the beginning)
So it took me a while to buy into the hype.
So for the last two years, I’ve used the free versions of Claude, ChatGPT, and Gemini simultaneously because I wanted to compare the results. And I used them on almost a daily basis. When Claude 3.5 Sonnet came out, in my comparisons and use cases, it quickly became the top tool for me, but then started cutting me off. So after two years of free, I paid for a subscription that day. And 3.7 is even better.
So I decided to give “vibe coding” a try, but with Claude, so I learned about MCPs. There are plenty of tutorials out there, but they kind of stopped with setting it up. And I wanted to show you how far you could on a project in about 2 hours. You know, a reason why to go through all of this trouble.
What are Model Context Protocol Servers?
Model Context Protocol allows Claude and other AI chat tools to connect to data sources and external tools. It lets Claude reach out and interact with other stuff. For example, your file system. So instead of adding one file at a time to a chat window, you can add the whole filesystem.
For this post, I installed two packages which gave me 20 MCP Tools:
- @wonderwhy-er/desktop-commander: This is server that allows Claude desktop app to execute long-running terminal commands on your computer and manage processes through Model Context Protocol (MCP) + Built on top of MCP Filesystem Server to provide additional search and replace file editing capabilities .
- @modelcontextprotocol/server-sequential-thinking: An MCP server implementation that provides a tool for dynamic and reflective problem-solving through a structured thinking process.
How to Add MCP (Model Context Protocol) Servers to Claude Desktop
Warning: This is not untechnical! But maybe that’s better. Because even though “vibe coding” can speed things up, having some technical knowledge can go a long way.
I use nvm. So, maybe that why I had so many issues. I started with one tutorial that told me all I had to do was run these commands:
npx -y @smithery/cli install @wonderwhy-er/desktop-commander --client claude
npx -y @smithery/cli@latest install @smithery-ai/server-sequential-thinking --client claude
And that didn’t work for me. I got a Could not attach to MCP server filesystem error.
Then another that told me all I had to do was create a wrapper for nvm and use that. Same error.
This is what finally worked for me. Run these commands to install the MCP servers globally:
npm install -g @modelcontextprotocol/server-sequential-thinking
npm install -g @wonderwhy-er/desktop-commander
Then open Claude’s settings:
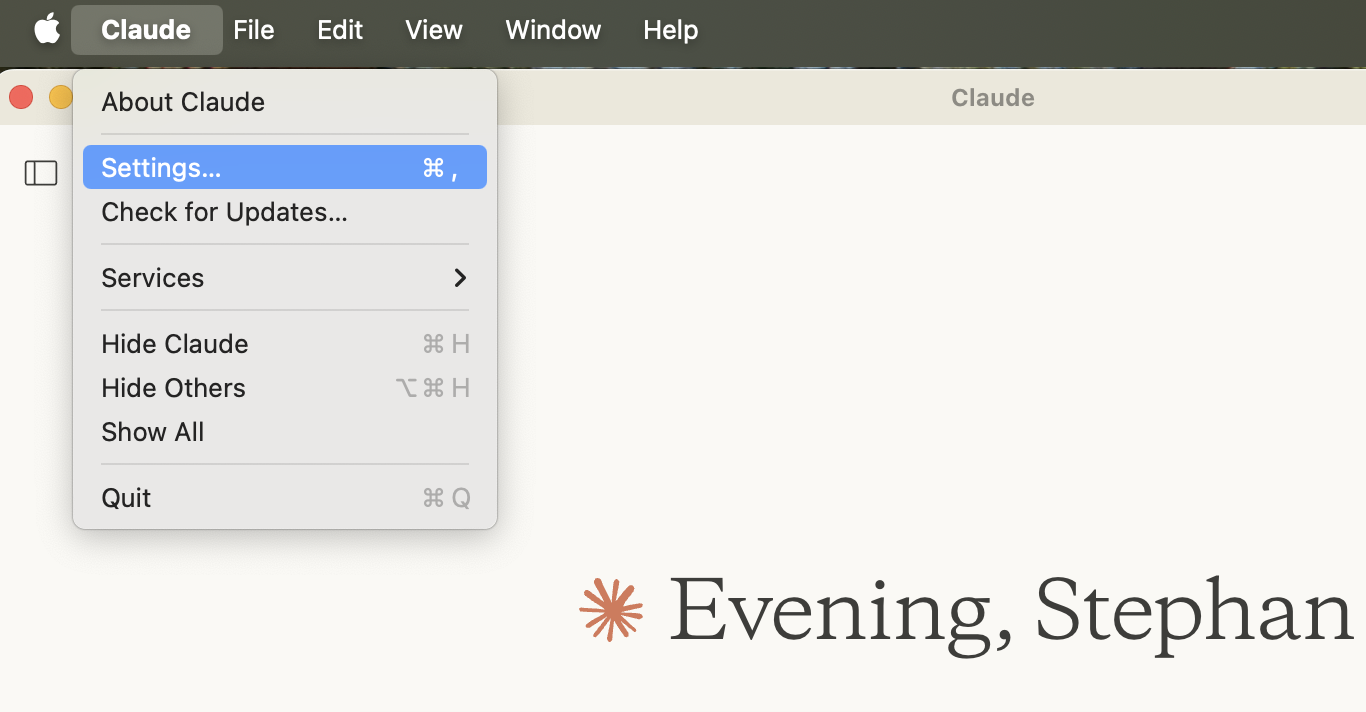
Then open the Config file manually by clicking Edit Config in the Developer section:
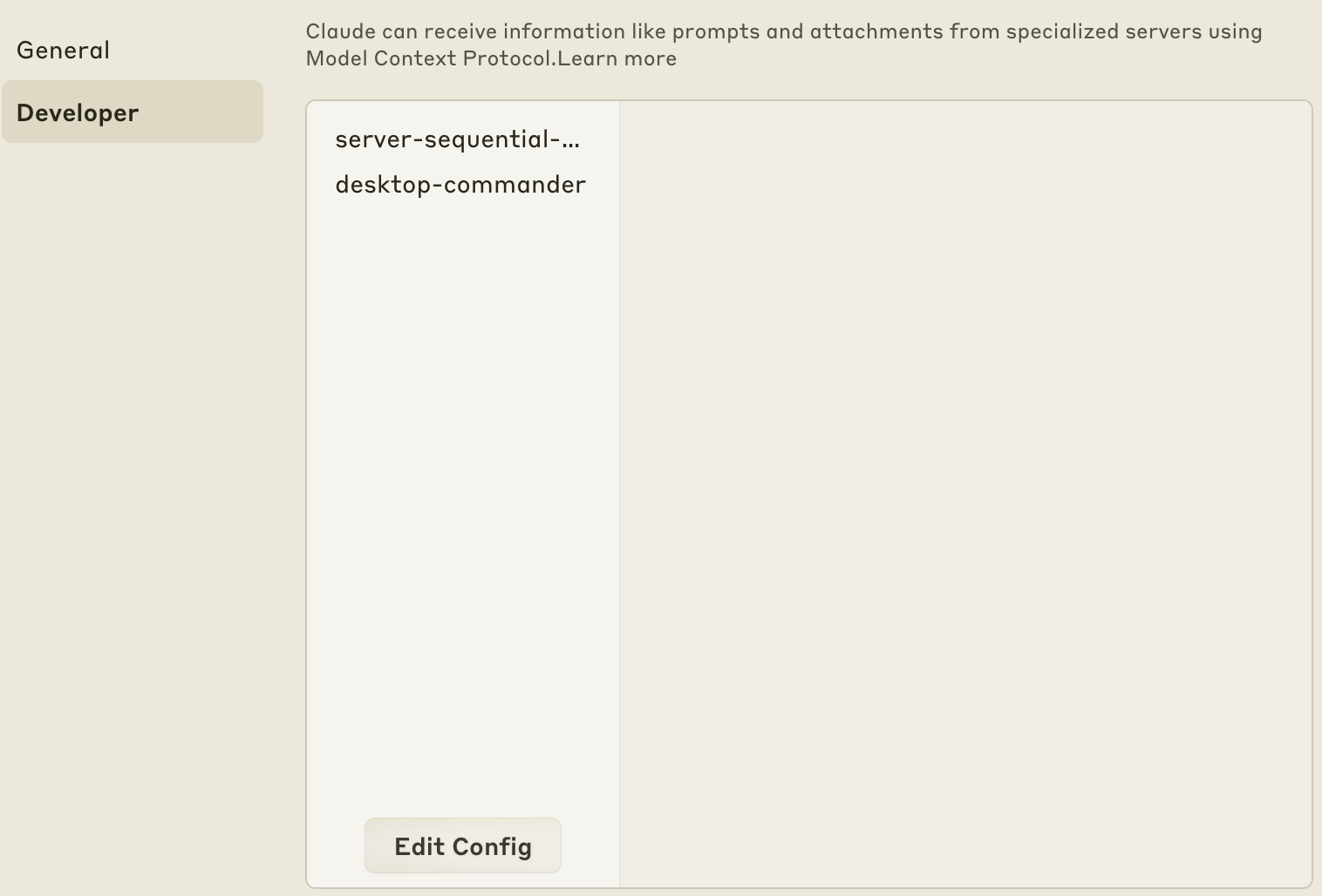
This will open the folder with claude_desktop_config.json selected. Open the file and hard code the paths of your node installation and the index file of the dist folder (at least for these two MCP servers) .
{
"mcpServers": {
"server-sequential-thinking": {
"command": "/Users/YOUR_USERNAME/.nvm/versions/node/v20.16.0/bin/node",
"args": [
"/Users/YOUR_USERNAME/.nvm/versions/node/v20.16.0/lib/node_modules/@modelcontextprotocol/server-sequential-thinking/dist/index.js"
]
},
"desktop-commander": {
"command": "/Users/YOUR_USERNAME/.nvm/versions/node/v20.16.0/bin/node",
"args": [
"/Users/YOUR_USERNAME/.nvm/versions/node/v20.16.0/lib/node_modules/@wonderwhy-er/desktop-commander/dist/index.js"
]
}
}
}
You can the location of the node installation you are using by running this command:
which node
Which will return something like this:
/Users/YOUR_USERNAME/.nvm/versions/node/v20.16.0/bin/node
Just replace YOUR_USERNAME in the config file with your actual username and the version number with the version number of your node installation. And it worked. Then I needed something to build.
The Idea
I have had this idea for a new project for a while and just kept putting it on the back burner because I knew it would take some time. It seemed like a good choice for this experiment:
- Build a website using a static site generator: My blog uses Jekyll. I really don’t care for Ruby and Gatsby has more features, plugins, and themes. I know JavaScript well but not Gatsby, so there would be a learning curve. Also, go ahead and hack my static site. The data isn’t there.
- Create a directory of writing markets: I have used Python Scrapy often and am good with it, but setting up a scraper for each site does take time.
- Create a newsletter that notifies subscribers of new markets: I have tried building newsletters before. My time is often limited because when there is freelance work I do it, more than 40,000 words this month. This will provide constant weekly content.
- Profit!
There is actually more I plan on doing after that, but that should get and keep things going.
The First Night Coding with Claude
Tips:
- Add your code to a git repo and commit when things work, so if anything goes south, you can revert back to a working state.
- Claude had trouble with it detecting my node version, so I would ask it if it knows your version of node. If it spits out the wrong value, tell it your actual node version and tell it to use that version when creating files. Or it will generate buggy code, but when I told it the actual version of node it quickly fixed everything.
The first night, I messed with the setup and then only had about a half hour left, so I worked on the Gatsby part of the app. I already had a basic installation but hadn’t made any changes to it. And if you’ve ever done that, you know how basic it is. This my first prompt and I really didn’t expect much:
In /path/my/project/is/in, I am building a Gatsby site. I want a nice looking theme and I want the standard blog+pages type of structure.
Each time it accesses a new folder, it will ask for permission. Sometimes it seems like it asks way too many times but it eventually stops. I actually forgot to take this screenshot, so I created another project to update the theme on my Jekyll blog which is over a decade old. In that case, it actually told me to create another branch in git to work on those changes.
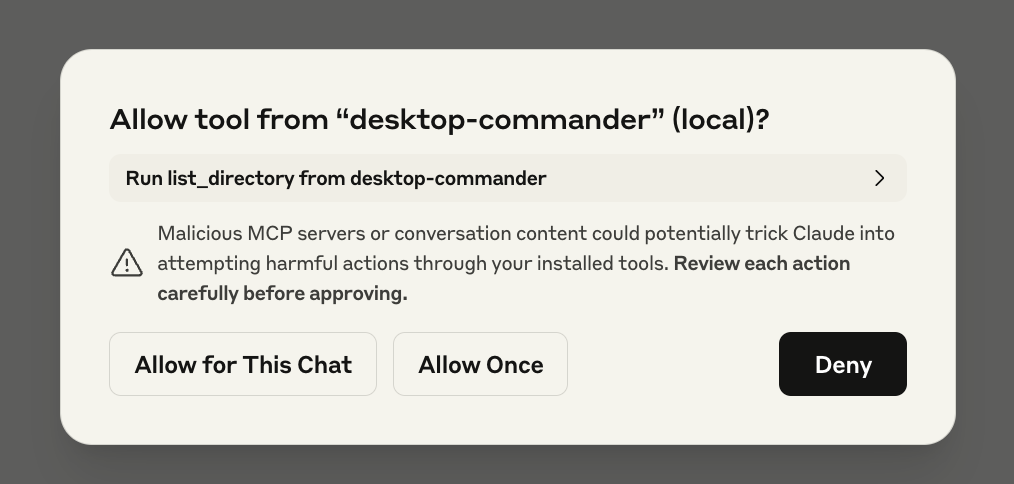
Once you allow it to access a folder, its off and running:
The I just told it to Continue a few times. When there was an error, I told it about it and it fixed it. This is where I ran into the node version mismatch, but once I told it my version, it fixed things. When it was done, it told me how to run it:
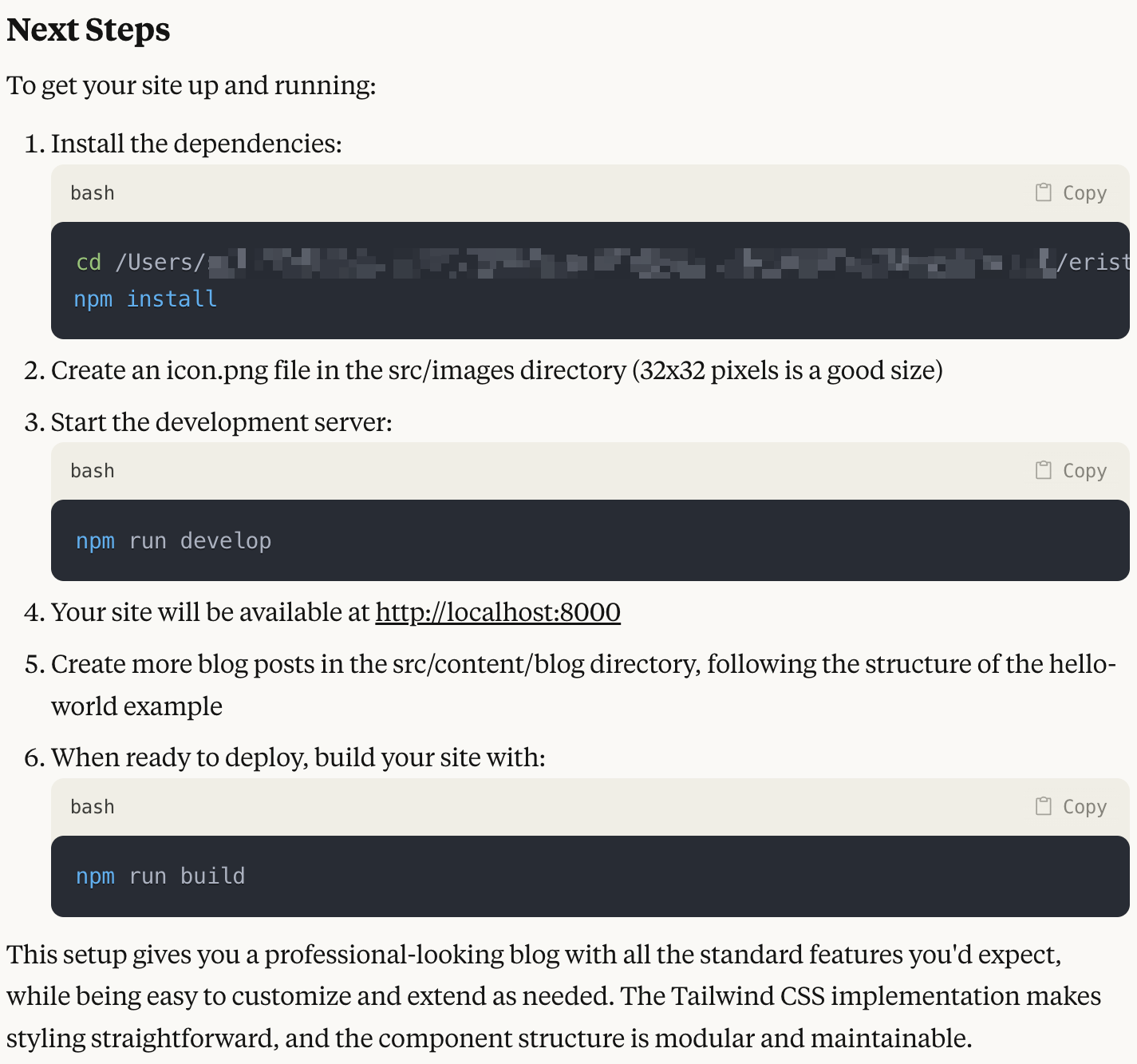
So I wasn’t sure what to expect but here’s what I got when I ran it:
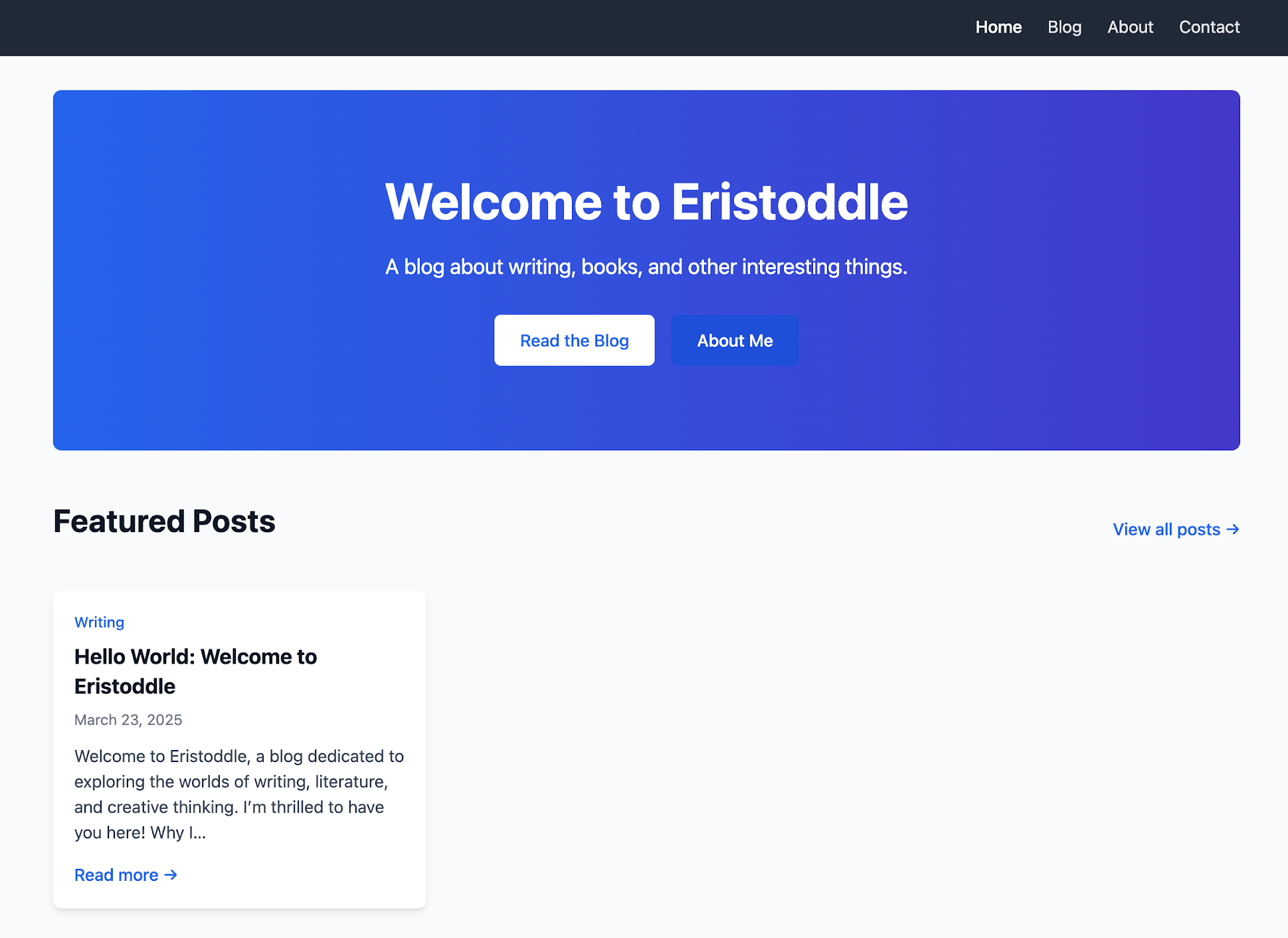
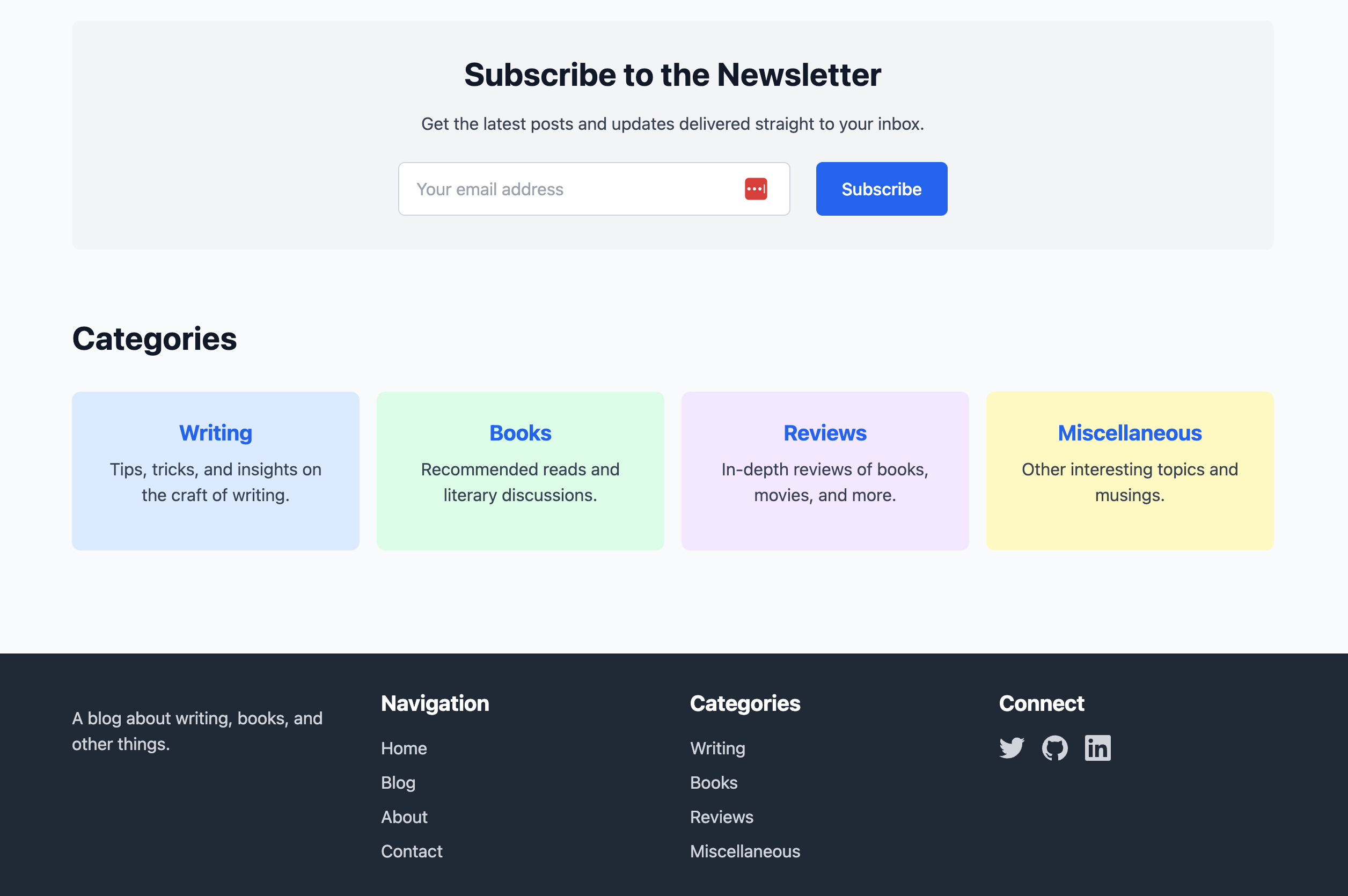
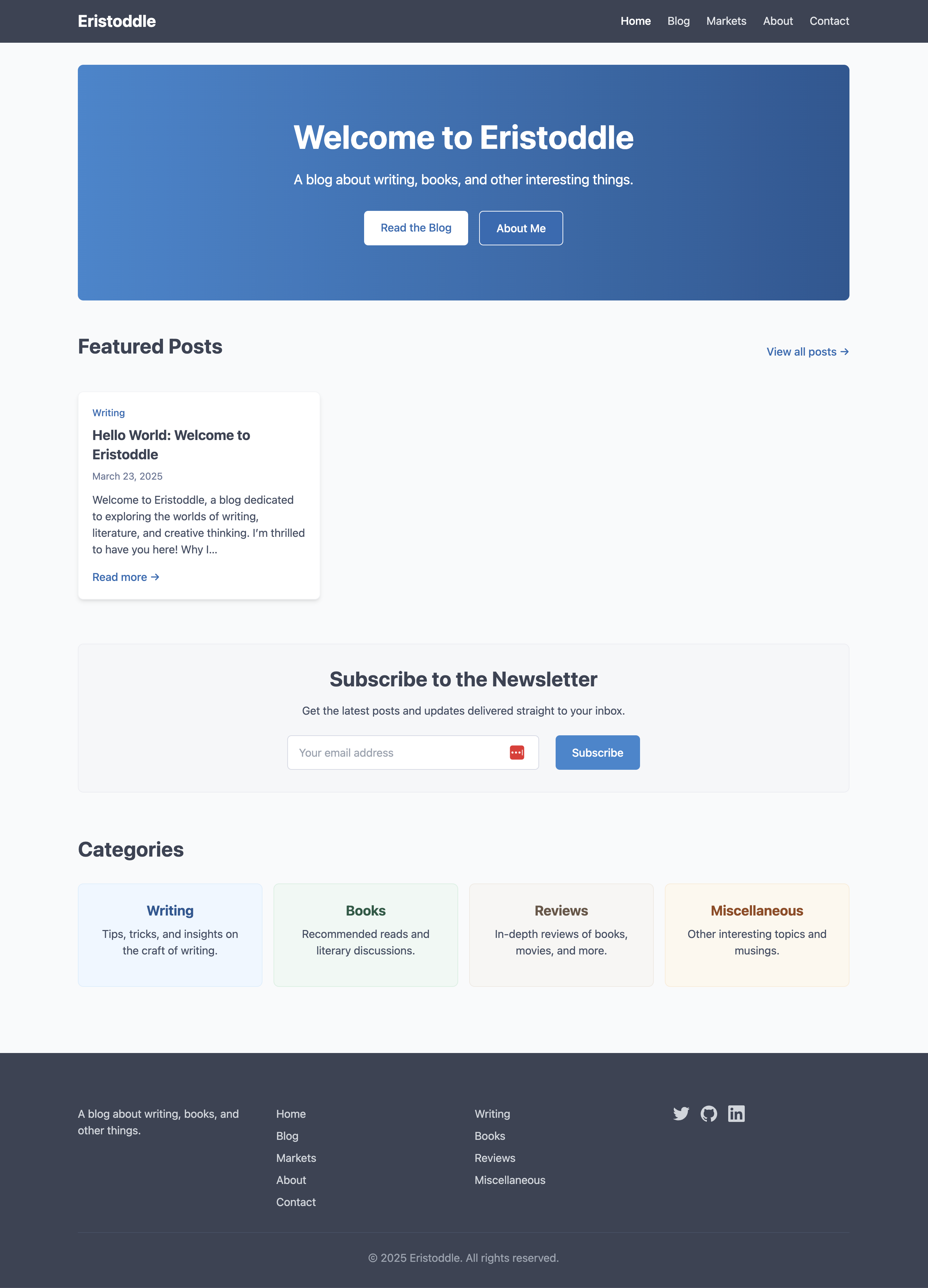
A little bit bright and primary colored for me, but a good start. So I told it:
I want to make the colors in the theme more mellow. Right now they are bold and primary colors.
Not much of a prompt, but it gave me this, which is better. I will tweak it later, but I wanted to get onto other things:
I also told it:
What if in the future, I wanted to scrape some data from websites and use that data to generate pages. These will be writing markets, so I would probably want to create a different type of page for them.
After some back and forth on what format I wanted to store each market as, I choose a JSON file per market and got this and the filters and search work well. It just added that without me asking for it:
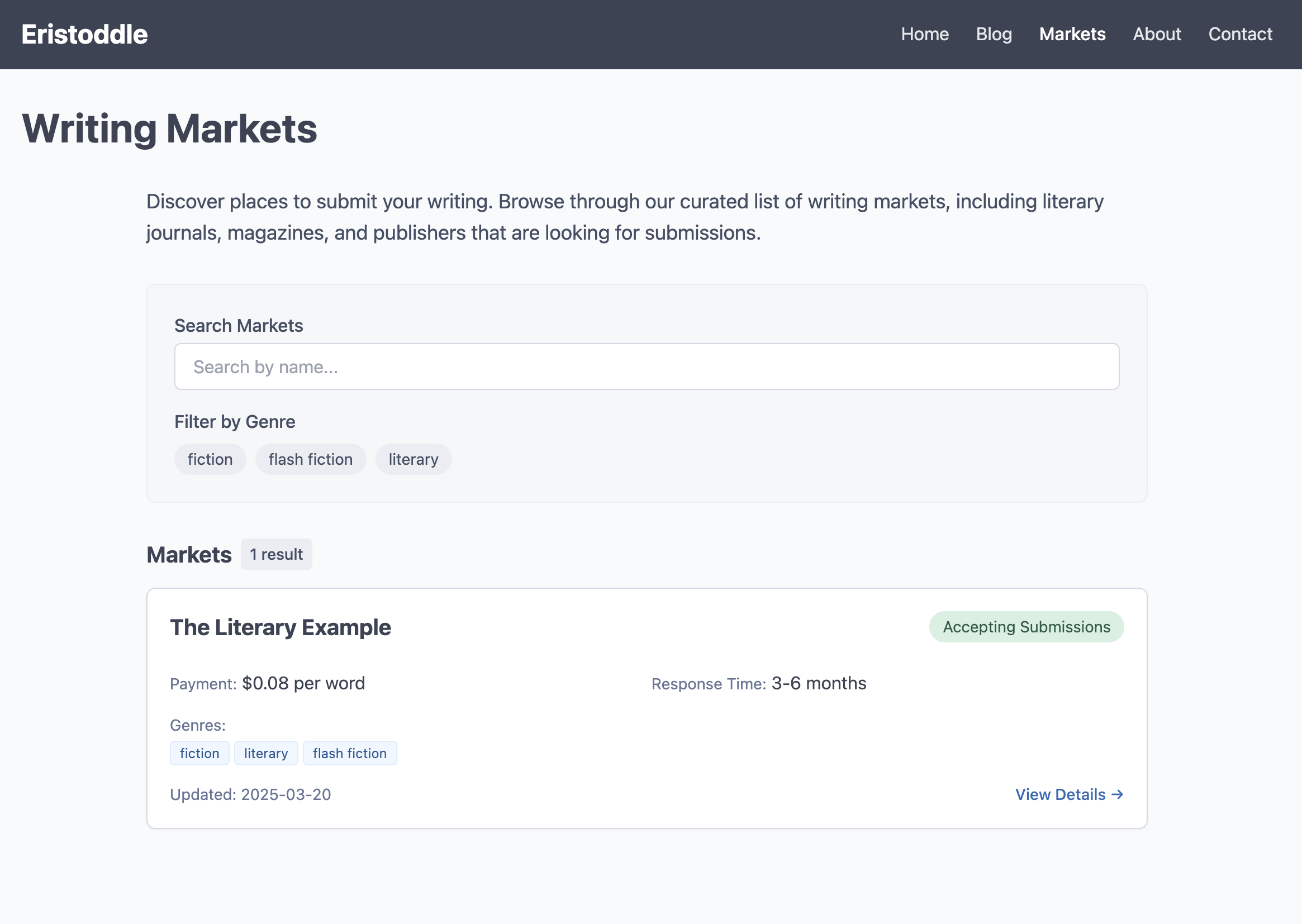
The Second Night
The second night, I also had around an hour. This night I wanted to create a scraper to provide data for the site. This was my first prompt:
I am building a gatsby project here: /my/project/directory for a blog and to list writing markets. You can see the structure in /my/project/directory/src/data/markets/sample-market.json. That may have to change as I go, as well as its templates. But for now I want to get started on a webscraper project to generate the json files for the gatsby site in /my/project/directory/data. I am not sure what to use for that just yet. I want to be able to eventually run it on cron.
I gave me a project summary and asked me if I wanted to continue.

I will probably see if it will refactor this with Scrapy later and see what happens, but I told it that was find and all I did after that was tell it to continue 4 or 5 times and here is the final result:

And it did kind of work. I didn’t guide it very much and it was a good start. It scraped some markets and put it in the folder in JSON format, but only about 8. But like I said, I wanted to see what it would do without much guidance.
Future Plans
I am actually going to work on this a little more tonight. Some things I’m thinking of include:
- Eventually tweaking the theme. Putting it off because I know it can be a time suck when I am not really sure what I want.
- Change the scraper to use Python and Scrapy so I know how to work with it better.
- Create dockerfiles for each project, especially the Gatsby one. A custom Docker image for my Jekyll blog makes deployment quick.
- Find out what this is.
It still has a long way to go but this is only part one and I’ll write about it as I go.
Part 2 is here: Vibe Coding With Claude Desktop and MCP Part 2 - Switching to Scrapy
Related Posts

I Burned Out on Vibe Coding, Came Back, and Rewrote Everything
After months away from side projects, I came back and realized my vibe-coded apps were prototypes. So I started over.

Verdent AI - When Your AI Coding Assistant Finishes Before You Can Get Coffee
I expected the same old process with coding tools and then was given a beta account for Verdent.

The Great Vibe Coding Experiment - How I Built 15 Projects with AI in My Spare Time
Plus the 80 page vibe coding/spec-driven development report Claude generated from my Obsidian notes for me

How I Built Two Obsidian Plugins While Kiro AI Did Most of the Work
Kiro helped me build two Obsidian plugins in 6-8 hours.